Data extraction (“Screen scraping” ) is a very important technique in data migration and integration scenarios. With its accurate OCR screen scraping features UI.Vision RPA essentially adds an “Data API” to every Windows, Mac and Linux application. This includes terminal, remote desktop (RDP), mobile phone emulators and even the new Amazon (AWS) AppStream secure application streaming service.
Screen scraping: We use OCRExtractRelative to extract the temperature from the remote desktop display of a smartphone app.
The sections below describe how to do screen scraping with UI.Vision RPA technically. Visual screen scraping can be used on the desktop and in the browser. For browser automation, screen scraping inside the browser is the only option if you want to extract data from a PDF, image or video. If the data is part of a regular website, you have the additional option to do web scraping with selenium ide commands.
UI.Vision RPA can use OCR to search for text on the screen. Optical Character Recognition (OCR) works on screenshots of the rendered web page. Just like the automated UI test commands, it works independently of the HTML page source code and document browser object. Thus, it works equally well on a simple website and on highly complex websites, canvas objects, inside images and videos and for PDF testing.
 Enable and test the text recognition on the OCR tab, and combine them with XClick.
Enable and test the text recognition on the OCR tab, and combine them with XClick.
Do you need to extract values from a video, scrape text from an image or extract text from a PDF? Then the OCRExtract commands helps. As the name suggests, it uses OCR to get the information. There are two ways to specify the text to extract:
This method is the easiest. UI.Vision RPA looks for the image, and then extracts the text from it. But if the content of the image area changes a lot, then the image is no longer found reliably. That is why we recommend to use OCRExtractRelative.
This method uses the green/pink box scheme, as described in the relative clicks section. The key difference here is that the content of the pink box is not clicked, but OCR'ed. And the OCR text result is stored in the variable. So only the content of the pink rectangle is used as input for OCR. No other data leaves the local system.
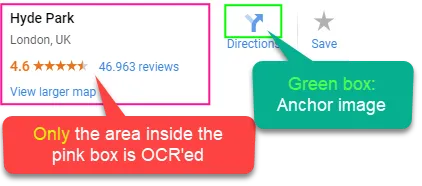 Only the area inside the pink box is used as input for OCR.
Only the area inside the pink box is used as input for OCR.
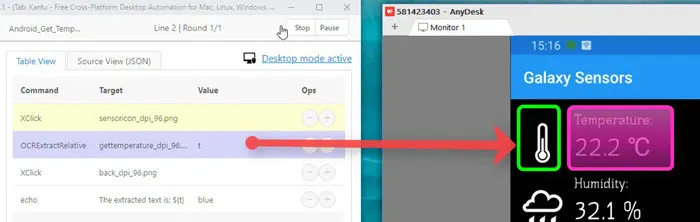 Here we read the temperature from a mobile phone app via a remote desktop connection.
Here we read the temperature from a mobile phone app via a remote desktop connection.
OCRExtractRelative is explained in this video. The green/pink box principle is used for all ....Relative commands. The green box is always the anchor image. The difference is the meaning of the pink box: (1) For OCR (as in the video), the pink box marks the text area to read. (2) For visionLimitSearchAreaRelative the pink box marks the new search area for computer vision. (3) For XClickRelative/XMoveRelative the middle (center) of the pink box marks the point to click.
This method works similar to XClickTextRelative - it defines the position relative to a word on the screen. Example: OCRExtractByTextRelative | abc#R100,-50H80W150 - it defines an extraction box of height 80 and width 150 at the location 100,-50 relative to the word "abc". If no height and width are used, the default values of H100 and W200 are used for the extraction area. Hint: Use the "FIND" button on the IDE to test your parameters. Ui.Vision will draw lines and boxes around the location(s) it finds.
The OCRExtractRelative command is the best solution to extract text from PDF for specific coordinates. You load the PDF into Chrome, and then use OCRExtractRelative command to find the area with the text and extract it. This is also called zonal OCR. UI.Vision RPA ships with the "DemoPDFTest_with_OCR" macro that shows how to get text from any PDF.
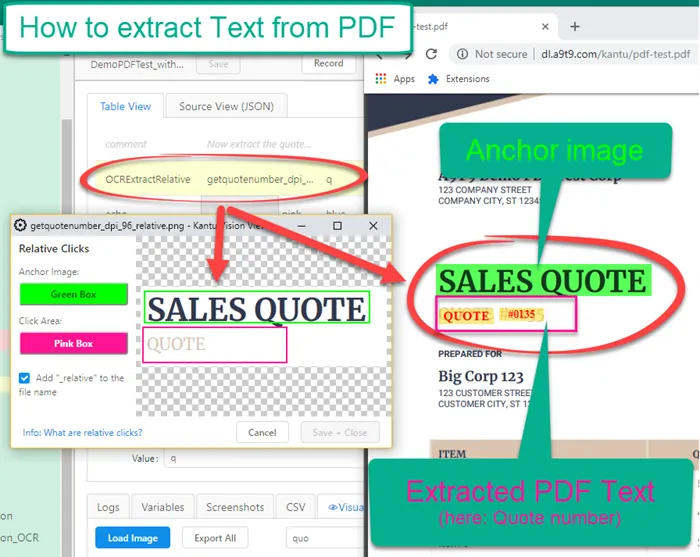 OCRExtractRelative runs Zonal OCR on area marked with the pink box.
OCRExtractRelative runs Zonal OCR on area marked with the pink box.
Another method is regex=(regular expression). The regular expression is applied to the OCR result of the complete active screenshot area, and the match(es) are returned. Conceptually the OCRExtract | regex=.... command works just as sourceExtract | regex=... . The key difference is that OCRExtract regex works on the OCR text result, and the sourceSearch regex works on the HTML page source code. So the "only" difference is the input, the regular expression logic is the same.
How to debug screen-scraping with OCRExtractRelative.
The OCR quality is very high by default. The RPA software uses the companion OCR.Space OCR API (also from us). You can use the following parameters (= internal variables) to control the quality:
If you still encounter OCR quality issues, please ask in the RPA software forum.
These commands use OCR to find a certain text and then do something.
Robotic Process Automation: Text recognition and XClick combined are very useful for robotic process automation (RPA). When you specify XClick with OCR text as input, UI.Vision RPA searches for the text, and then clicks on it. They key difference to the "good old" selenium IDE Click (locator) commands is that this works 100% visually. So it works absolutely on every web page, image, video, PDF and during robotic desktop automation (RDA). For more information see the XClick command.
To click the X-th occurrence of a text string, use ocr=text@pos=X. The occurrences are counted from top left to bottom right. Another option to exclude some matches is to limit the search area.

Every OCR search sets the ${!OCRX} and ${!OCRY} internal variables if a match is found. If more than one match is found, the location of the first match is used. The x/y value is the center of bounding rectangle of the found OCR word(s). This is the value that is used with the "XClick | Ocr=..." command. For image search we have !imageX/!imageY values and for OCR search the !ocrX/!ocrY value pair.
The OCRSearch command searches for a given text (partial matches ok) and stores the number of matches in the variable. If you want to check if the x-th match of a text exists, you can use the @pos parameter: OCRSearch | text to search@pos=x | variable. Conceptually the OCRSearch command is similar to sourceSearch. The key difference is that OCRSearch works visually on a screenshot, and the sourceSearch command works on the HTML page source code.
TopHow does UI.Vision RPA generate the OCR results? By design, UI.Vision RPA operates 100% locally and no data ever leaves your machine. The OCR feature is different (if the local XModule OCR is not installed) and that is why it is disabled by default. There are 3 different settings on the UI.Vision RPA OCR tab:
This is the default settings. All OCR commands are blocked and no data leaves your machine.
The Ui.Vision XModule includes integrated OCR support. This OCR has a few limitations comparted to the online OCR (less languages, somewhat reduced accuracy) but it runs 100% local so it is very fast and work on machines without Internet connection. XModule OCR is currently available for Windows and Mac (not Linux yet).
To use XModule OCR you must install the XModules native app. The local OCR engine is bundled with the installer.Once installed, you can switch to XModule RPA OCR on the OCR Settings page. The language dropdown becomes automatically populated with the available offline languages.
When the OCR commands are enabled, UI.Vision RPA takes a screenshot of the visible part of the website inside the browser and sends it to the OCR API for processing (with OCRExtract, only the part inside the pink box is send). The OCR API returns the result, and UI.Vision RPA uses it to find the right word on the right place on the screen. On a fast internet connection, the run time for the OCR process is typically less than a second. After the screenshot is processed, it is deleted from the OCR server. Absolutely nothing is stored on the server. We know this for sure, because the OCR.space OCR API is developed in-house. OCR.space has the best, most strict privacy policy from all OCR providers.
Since we use the OCR.space OCR engine, the OCR API documentation, the list of supported OCR languages, tips and tricks apply to the UI.Vision RPA OCR features as well. On the OCR tab, you can define the default OCR language. And with the !OCRLanguage internal variable you can set the OCR language per macro. !OCRLanguage takes the 3-letter ISO language code as input.
The integrated XModule OCR engine has the number 99. In addition, the RPA software can use online OCR API engines. Example: With store | 2 | !ocrEngine you can switch to the second OCR engine. OCR engine 2 is a bit slower, but often better for number and special character OCR.
UI.Vision RPA includes 100 free OCR conversions per day. The conversion counter is automatically reset every day. More conversions can be purchased as part of our XModule PRO and Enterprise plans.
We understand that some organizations can not allow the use of any cloud services at all. For Windows and Mac systems, we solved this problem by integrating 100% local OCR into the XModule. But for Linux this was not possible yet. So if your organization wants to run the RPA software with local OCR on Linux, the OCR Server addon is required. In this case we recommend our on-premise UI.Vision RPA OCR server installation. The UI.Vision RPA OCR Server is a special version of the OCR.space Local Self-hosted, On-Premise OCR Server. It runs 100% locally and requires no Internet connection. One UI.Vision RPA Offline OCR server can be used with all UI.Vision RPA installations in your company - so only one license is required. After the OCR server is installed, enter the URL of the server and its api key on the UI.Vision RPA OCR settings tab. The UI.Vision RPA OCR server is available as paid local OCR add-on.
TopTips for debugging OCR automation issues:
Tip 1: UI.Vision RPA always stores the last screenshot that it makes as "_lastscreenshot" on the visual tab. So you can check there if the screenshot contains the information that you need.
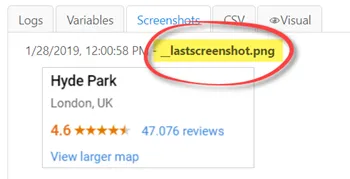 The last screenshot taken as input for OCR and computer vision is stored as _lastscreenshot. So you see what UI.Vision RPA sees.
The last screenshot taken as input for OCR and computer vision is stored as _lastscreenshot. So you see what UI.Vision RPA sees.
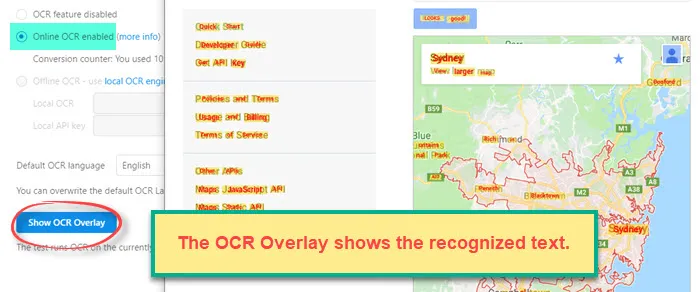
Tip 2: The "Test OCR button" on the OCR tab and the "Find" button when OCRSearch is selected as command both trigger an OCR conversion and display the result as overlay in the browser. This allows you to check if the OCR conversion was accurate. If you find any problems, please report them to us.
UI.Vision RPA contains a command-line application programming interface (API) to automate more complicated tasks and integrate with other programs or scripts for complete Robotic Process Automation (RPA).
Screen Scraping means getting information from a screenshot, terminal session or video image. Web scraping means getting information from inside the web browser. If you want to extract data from inside the Firefox or Chrome browser see Web scraping with Selenium IDE.