UI.Vision RPA User Manual
AI-powered Visual Web Automation
UI.Vision RPA's image and text recognition allow you to write automated visual tests with UI.Vision RPA - this makes UI.Vision RPA the first and only Chrome and Firefox extension (and Selenium IDE) that has "👁👁 eyes". For more information please see visual UI Testing and the XClick command.
AI-powered Visual Desktop Automation
UI.Vision RPA can not only see and automate everything inside the web browser. The same image and text recognition technology can automate your desktop as well (Robotic Process Automation, RPA). For more information please see Desktop Automation and the XClick command.
Automation by Example
Often it is best to learn from examples. UI.Vision RPA installs many ready-to-run demo macros that showcase its features and all important commands.
RPA Software Screencasts
The RPA Software Youtube channel has UI.Vision videos that highlight and demo the RPA features. For example:
- Web and Desktop Automation with UI Vision
- Codeless UI Automation for Desktop apps
- Testing Discord App Chat with XClick and XType ${KEY_ENTER}
- Automating Drag & Drop with Image Recognition
- Set Date Control
- Run one macro after another with the UI Vision command line API
Command Reference
Image-driven Commands (AI powered Web and Desktop Automation)
Selenium IDE Commands (see also How is UI.Vision RPA related to Selenium IDE?)
Web Scraping with Selenium IDE
Command Line API Commands - control UI.Vision RPA from any program or script
TopFlow Control
UI.Vision RPA was the first web macro recorder with built-in flow control commands like if/else/endif, while/endWhile or GotoIf. Follow the links for more details and examples.
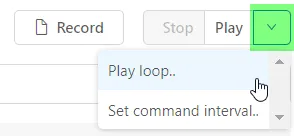
TopLoop button
The dropdown next to the Play button contains the loop feature - run macros as a loop. Looping a macro is useful for doing basic load testing with the Selenium IDE, for performance monitoring or to simply test the stability for the test case (macro) itself. The csvRead command to read a CSV file line by line makes also use of the LOOP button.
Read and write CSV files
Comma-separated values (CSV) files are useful as data input for data-driven testing/automation or as data output for web scraping. In UI.Vision RPA for Chrome the csvRead and csvReadArray commands give you access the data inside CSV files, and the csvSave and csvSaveArray commands allow you to write test results or extracted values to a CSV file.
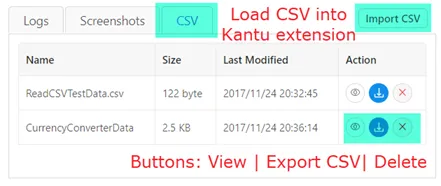
The CSV manager tab (shown in the screenshot) allows you to import, export, view and delete CSV files to the local storage of the extension. So the CSV files are not directly accessed from the hard drive, but they are stored inside the web browser. The reason for this is that modern browser extension have no access to your hard drive. Just like with the macros, all CSV files are stored locally inside your browser (technically called local storage), nothing is uploaded to any kind of cloud service.
If you have the UI.Vision RPA FileAccess XModule installed, you can switch the macro storage mode to Hard-Drive Storage. This will also redirect all CSV read and write operation directly to the hard drive. By default, CSV files are then stored in the "UIVision/datasources" folder.
TopAutomating File Upload
Content moved: The file upload tutorial has now its own page: File uploads with Selenium IDE and File uploads in Firefox.
Automating File Download
If you all need is a simple download, there is nothing special to do. If a click command triggers a download, UI.Vision RPA handles it automatically. By default, UI.Vision RPA does not stop and wait for the download to complete, the macro continues with the next command(s).
OnDownload | new file name | (wait for download to complete:) true/false
For more control over the download there is the OnDownload command. It allows you to overwrite the default file name with a custom name. And with "true" in the 3rd column you tell UI.Vision RPA to wait for a download to complete before continuing with the next command. UI.Vision RPA waits for max. timeout_download seconds. This option is great for checking the performance (download speed) of a file download. If you need to measure the exact download time, you can do that with the value of the !RUNTIME internal variable. The max. wait time between a mouse click on the link and the actual download start is limited by timeout_wait. OnDownload can be at any place in the macro as long as it is reached before the download is triggered.
TopInternal variables
Some parameters can be controlled via Internal variables. All internal variables are valid only per macro run and they do not change the global default values. In other words, internal variables overwrite global default values inside the macro they are used.
-
!clipboard (read/write) - write to or read from the computer's clipboard (copy and paste).
-
${!cmd_var1}, ${!cmd_var2},
${!cmd_var2}
(read) - the value of these three variables can be set via the command line with the cmd_var1/2/3 switches.
-
!col1, !COL2,... (read only) -
Values read from CSV file with csvRead
-
!csvLine (read/write) - storing values to this variable appends them to the line used
by csvSave. Use store | NULL | !csvLine to overwrite (not append) the current values.
-
!csvReadMaxRow (read) -
In some cases you may need to now how many lines are in a CSV file, or you want to read the last (most recently added)
line of a CSV file. In both cases the internal variable !csvReadMaxRow can help. After the first csvRead,
this value is set the number of lines in the CSV
(example here)
-
!csvReadStatus (read) - true if the last csvRead command was successful.
Typically false if there are no more lines in the CSV file. So together with the while
command, this can be used to read CSV files where the number of rows is unknown. Please see the DemoReadCSVwithWhile macro for a code example.
-
!csvReadLineNumber (read/write) - true sets the line number for the
csvRead command to read. If not used, the value of !LOOP is used for the line number and
!csvReadLineNumber is set to the same value.
-
!ErrorIgnore (read/write) - This is a very useful internal variable.
If set to true with store | true | !errorIgnore the macro execution continues after an error.
It is often used with flow control or to test/click links that sometimes exist and sometimes not.
You can change back to the normal behavior at any point
in the macro with store | false | !errorIgnore. Related forum post: RPA Error handling options
-
!LastCommandOK (read only) [DEPRECATED, use !statusok instead] - contains the status of the last executed command (true of successful,
or false if the command encountered an error. Use with !ErrorIgnore set to true so the macro execution continues after an error.
The ECHO command that does not influence the status, so it can be used for logging the value of !LastCommandOK without changing its value.
-
!Last_Downloaded_File_Name (read only) Get the name of the downloaded file. This requires ONDOWNLOAD to be inside the macro.
-
!statusOK (read/write) - contains the status of the macro execution. Once an error happens
!statusOK is set to FALSE.
Typically this variable is used to get the result of the VERIFY... commands and the storeText / storeValue / storeChecked / storeAttribute web scraping commands, which do not stop at an error. If you want to use it with other commands then remember to set !ErrorIgnore to true so the macro execution continues after an error. Only then will !statusOK be useful, as otherwise the macro stops at an error anyway.
!statusOK does not get reset by a successful command. Once !statusOK is set to "false" by an error, it remains "false", even if the next commands succeed. But you can use store | true | !StatusOK to manually reset it. Related forum post Simulate Try/Catch in Selenium IDE
-
!StringEscape (read/write) –
If true \n \r are interpreted as escape sequence (default). If false they are interpreted literally
(more details). This applies to TYPE and SENDKEYS, but not XTYPE.
-
!LOOP (read only) – current value of the loop counter (1,2,3… etc).
Great for use with @POS=${!LOOP} to cycle through a list of links.
-
!MACRONAME (read) - Name of the macro this command is in
-
- !OCRLanguage=ENG/..., !OCREngine=1/2/99 => Please see
OCR screen scraping for details on how to control the text recognition.
-
!REPLAYSPEED (read/write) - Set the replay speed to FAST (no delay between each step), MEDIUM (short, "human like" delay)
or "SLOW" (2 seconds delay). Another option is NODISPLAY. It stops IDE GUI updates for the fastest possible replay speed.
-
!RUNTIME (read) - Time elapsed since macro start.
This value is very useful for performance testing and performance monitoring
-
!RUNTIME (read) - Time elapsed since macro start.
This value is very useful for performance testing and performance monitoring
-
!GLOBAL_TESTSUITE_STOP_ON_ERROR (read/write) tells
UI Vision to stop the test suite execution after an error.
The default settings is "false", so by default the RPA software continues to run all tests.
Note that this is a global variable, so you only need to set it in one of the macros of your test suite!
Typically, of course, you would use it in the first macro.
-
!TIMEOUT_DOWNLOAD (read/write) - Time limit for file downloads if UI.Vision RPA is told to wait for a
download to complete via OnDownload | file name | true
-
!TIMEOUT_MACRO (read/write) - Limit for the overall macro runtime.
The default value is 300s (5 minutes).
-
!TIMEOUT_PAGELOAD (read/write) - How long to wait for page load
-
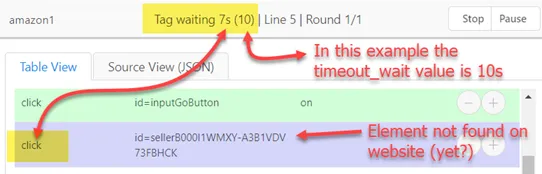
!TIMEOUT_WAIT (read/write) - How long to wait for an element to appear before reporting an element not found error
(implicit waiting)
-
!TIMES (read) - Loop counter for the times loop. In
!URL (read only) - contains current browser URL that you see in the address bar. Previously,
the storeLocation command was needed for this.
-
!WaitForVisible - by default the implicit waiting
waits for an element to appear and become
visible. If you do not want to wait for the element be visible (typically because it never becomes visible) use
store | false | !WaitForVisible. Then waiting
for visible is turned off for all following commands until you set it again to true.
Source Code Tab
The source code tab is the useful to view, search, edit and copy & paste source code snippets:
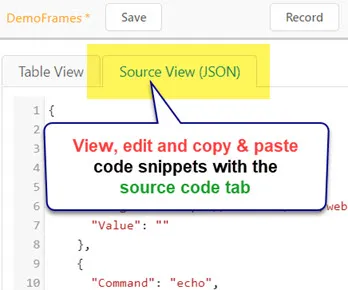 You can use the source code tab to copy and paste code snippets to/from the UI.Vision RPA forum.
If you paste code in the forum please remember use the code tag in the forum editor.
You can use the source code tab to copy and paste code snippets to/from the UI.Vision RPA forum.
If you paste code in the forum please remember use the code tag in the forum editor.
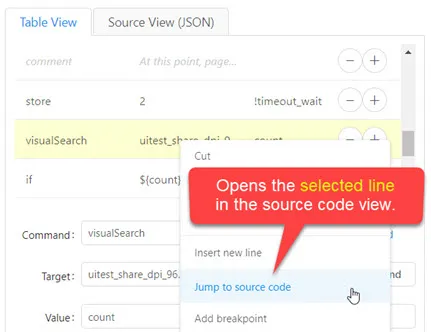 In the table view you can use the "Jump to source code" context menu item to
jump directly to the JSON code of the currently selected command. In other words, this feature opens the source code view tab and automatically scrolls down to the right position.
In the table view you can use the "Jump to source code" context menu item to
jump directly to the JSON code of the currently selected command. In other words, this feature opens the source code view tab and automatically scrolls down to the right position.
Performance Monitoring/Testing
The !RUNTIME internal variable contains the macro runtime and makes performance testing easy. In the example below we first click on the "Start OCR button " (OCR.space) and store the current run time in a variable. Then UI.Vision RPA waits for the result (= web element) to appear. Once the element is found and the macro execution continues we measure the time again by reading the current value of !RUNTIME. The difference is the runtime performance of this step. In a next step you can, for example, write the value of "TimeForThisStep" to a CSV file with the csvSave feature.
Performance Monitoring/Testing
The !RUNTIME internal variable contains the macro runtime and makes performance testing easy. In the example below we first click on the "Start OCR button " (OCR.space) and store the current run time in a variable. Then UI.Vision RPA waits for the result (= web element) to appear. Once the element is found and the macro execution continues we measure the time again by reading the current value of !RUNTIME. The difference is the runtime performance of this step. In a next step you can, for example, write the value of "TimeForThisStep" to a CSV file with the csvSave feature.
| click | link=Start OCR! | Start the process to measure (in this case an OCR conversion) | |
| store | ${!RUNTIME} | StartTime | Store the start time |
| click | //*[@id="sucOrErrMessage"]/strong | Wait for the "Completed" message to appear... | |
| store | ${!RUNTIME} | EndTime | Log the current macro runtime |
| storeEval | ${!EndTime}-${!StartTime} | TimeforThisStep | Calculate the runtime of the "yellow" step,which is the difference between start and end time. |
Test status reporting
The background of each macro indicates its test status: White = not yet run, Green = last run was ok and red = last run had an error.

Setting the right macro replay speed
In (gear icon) > Replay Settings you can select the replay speed. FAST (no delay), MEDIUM (0.3s, default) and SLOW (2s). With FAST, UI.Vision RPA replays the macro as fast as it can. This is faster than any human could type, so on some websites that can cause problems, as they have not been tested for such a speed and sometimes Javascript code can not respond quickly enough. Typically MEDIUM is a good compromise between speed and being website-friendly. SLOW can be useful for testing and debugging.
You can change the default replay speed in the settings menu (see screenshot above) or inside a macro with store | SLOW/MEDIUM/FAST | !replayspeed.
TopPosition support in link text locator
With CLICK link=Download@POS=3 you instruct the IDE to use the n-th (here n=3) occurrence of a locator. This is useful, for example, if a have a website with many download links, and you want to click the n-th once. POS is only supported with the “normal text” locator link=... but not with XPATH and CSS selectors.
TopMore Example Macros (Test cases)
The UI.Vision RPA Selenium IDE github page contains the /test folder with plenty of test macros. You can download and import all macros/selenium IDE scripts at once. For this, use the "Gear icon => Import HTML" feature and then select all the macros/scripts that you want to import (we call the test cases often macros - this is the same. We use the word macros as some users use the extension not for web testing, but for web automation. There the word macro and macro recorder is very common.)
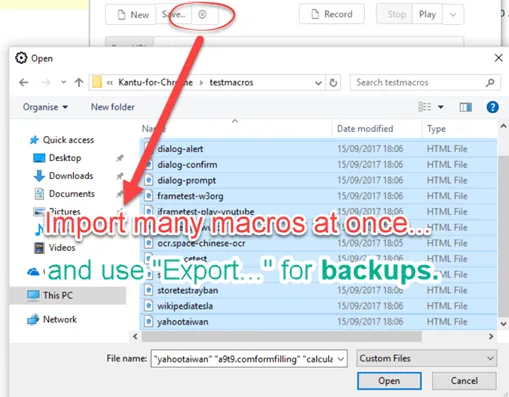
Tip: Backup your macros
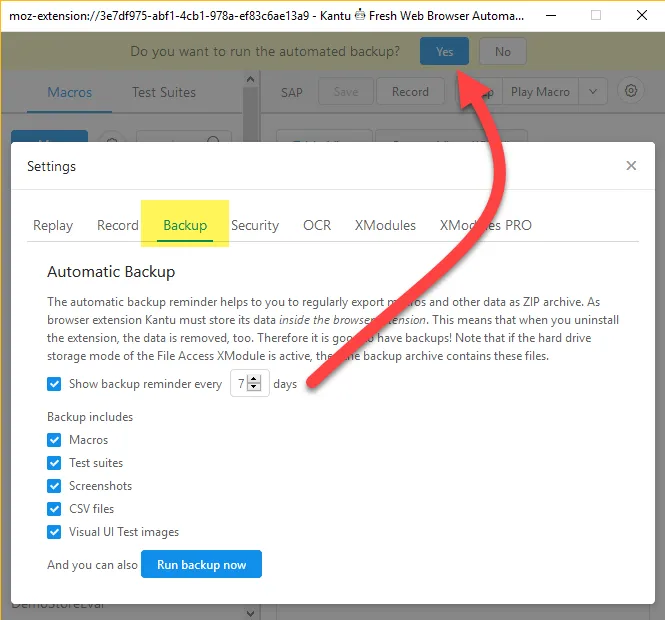
In the default storage mode macros, test suites and all UI.Vision RPA settings are stored inside your web browser in what is called technically HTML5 local storage. Nothing is copied or moved to the cloud. This means that once you uninstall the UI.Vision RPA extension, your macros are gone! You can use the "Export" feature to create backups of your important test cases, CSV data and images. The fastest way to export everything is to use the "Run backup now" button on the backup settings panel. It exports all data at once.
If you need to recover information from a backup, see this forum post on how to restore macros from a backup.
Command Line API
The command line API allows you to control all RPA features from any scripting or programming language. To start the RPA software via the command line you start the browser (e. g. Chrome) via the command line and load the special RPA startup page. You can generate the page on the "API" settings tab. It is always the same page, so you only need to generate it once:
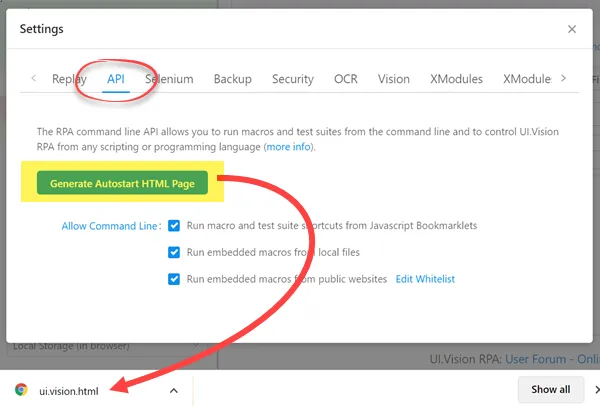
Then load the ui.vision.html website in the web browser and add ¯o=YourMacro - and the macro runs automatically! To skip the "Do you want to run this macro?" question, add the "?direct=1" switch to your local file URL (file:///...).
Important: Even so we mention the browser here, the command line feature works exactly the same in GUI desktop automation mode. The browser and the local website are just needed because the UI.Vision RPA core is technically implemented as browser extension. In other words, UI.Vision RPA can be used as part of a CI pipeline for web automation and for desktop automation.
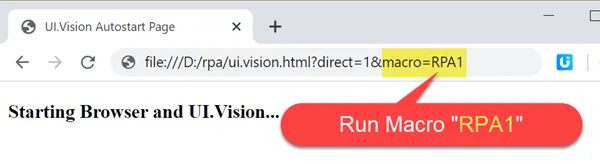
Allow UI.Vision RPA access to file URLs. This is only required in the Chrome and Edge browsers, since Firefox allows access
to file URLs by default:
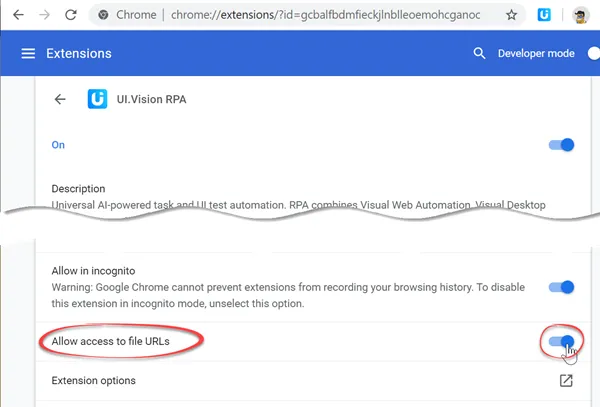
Example: A Windows batch file to run the RPA software from the command line on looks like this: "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" "file:///D:/test/ui.vision.html?direct=1¯o=MyLogin&savelog=c:/test/log1.txt"
The macro specified with macro=MyLogin is run. Note that you must use file:/// for the file path. If you would just start with "C:\..." you will get a "file not found" error for the HTML file due to the appended "?direct=1¯o=MyLogin&closeRPA=1&savelog=log1.txt" GET parameters. Windows is used as an example here, the command line feature also works on Mac and Linux as well. "ui.vision.html" is the exported launch page. IMPORTANT: Macro and Folder names are CASE-SENSITIVE.
A longer command line, this time with Firefox: "C:\Program Files\Mozilla Firefox\firefox.exe" "file:///D:/test/ui.vision.html?macro=demoframes&cmd_var1=hello%21world&cmd_var2=123&cmd_var3=ABC&closeRPA=1&closeBrowser=1&direct=1&savelog=logfirefox.txt" In this example we use the command line send some values to the macro and we close the RPA software and browser after the macro is done.
Command Line Demo Videos
CLI: Run one macro after another with Powershell.
Using the command line API from Node.js
Command Line API Source Code
You find all source code on Github:
- - Batch file
- - Node.js
- - Powershell
- - Python file
- - VBS
UI.Vision RPA as Automator alternative on Mac
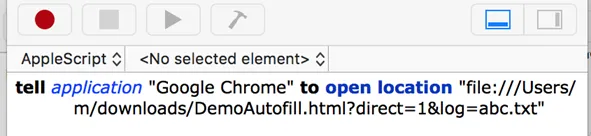
On MacOS you need to use AppleScript to start Chrome/Firefox with the file url. If you would only use the OPEN command, then the GET parameters behind the ? are lost. You can get AppleScript executed from a bash script or function, or from a Terminal by just prefixing it with "osascript". So the correct command line syntax for Mac is osascript -e 'tell application "Google Chrome" to open location "file:///Users/t/ui.vision.html?macro=TEST&direct=1&closeRPA=1&savelog=/user/desktop/demotestlog.txt"' Thanks to user Shunt/Timo for the forum post Launching UI.Vision RPA from Command Line on a Mac. We used their feedback to update this section.
Command Line Parameters
Note that in a strict technical sense these are not command line parameters, but "GET" parameters that are appended to the file URL of the "ui.vision.html" autorun HTML page that you are loading in the browser. But their purpose is just like that of real command line parameters, so we call them this way.
- - direct=1 - Skip the "Do you want to run this macro?" question.
- - closeBrowser=1 - Closes the Chrome browser when the macro is completed. The default is "0", the browser remains open. Screencast of a PowerShell script that uses CloseBrowser=0.
- - closeRPA=0 - Close UI.Vision RPA when the macro is completed. The default is "1", so UI.Vision RPA closes after the macro is done.
- - folder=foldername - exactly the same as the macro switch, but it runs all macros inside a folder. This means every folder can be used test suite. IMPORTANT: Folder names are CASE-SENSITIVE.
- - savelog=filename.txt - This saves the log (content of the Log tab) plus a header status header as a text file once the macro has completed. The log is saved whether the run was successful or not. The calling script (e. g. Batch file, Node.JS, Python, or PowerShell) can check for the existence of this file to make sure the macro run completed). The first line of the log file is always the status of the macro run (error or success, and the error message, if any). A second way to save the log file is to use the command localStorageExport | log. But unlike the command line option, this method does not add a header with status information to the top of the log. New with V8.1.3: The &savelog= parameter supports full paths now, e.g. savelog=c:/test/log.txt. If a full path is detected the log is saved directly (instead of triggering a download). This is faster and more reliable. We recommend to update your automation scripts to use this new feature. It requires the XModules to be installed.
- - storage=browser/xfile - This parameter tells UI.Vision RPA if the macro or testsuite folder to run can be found in the HTML5 browser storage or on the hard drive.
- - macro=folder1/subfolder1/macroname - Run the specified macro. IMPORTANT: Macro and folder names are CASE-SENSITIVE.
- - nodisplay=1 - Runs all macros in nodisplay mode. A macro-internal !replayspeed setting overwrites this global value.
- - cmd_var1=hello%21world, cmd_var2, cmd_var3 - Send values to a UI.Vision RPA macro from the command line. Inside the macro you can access the value with the internal variables. ${!cmd_var1}, ${!cmd_var2} and ${!cmd_var3}.
- - Examples: All the above switches are used in the Command Line Source Code Snippets.
See also: You can not only start UI.Vision RPA from a script via the command line, you can also start a script from within UI.Vision RPA with XRun.
Rarely used and deprecated command line options:
How to run UI.Vision RPA macros 24/7
Many applications of UI.Vision RPA require continuous operation of the software. Examples are the use of UI.Vision RPA as part of robotic process automation (RPA), extracting large volumes of information or web testing applications in general.
Problem: By design web browsers are not intended for 24x7 operations and running them repeatedly for several days can lead to undesirable effects, such as increased memory consumption ("memory leaks").
Solution: The UI.Vision RPA command line allows you to control the UI.Vision RPA operation. With the -savelog switch a calling script can easily check on the success of each macro run. The -closebrowser and -closeRPA switches allow you close Chrome and Firefox periodically to avoid memory leaks. And you can add code to terminate the Chrome or Firefox instances if they hang (e. g. using proc.kill() in Python or #taskkill /F /IM chrome.exe /T in Powershell).
Examples: Demo scripts for running UI.Vision RPA 24/7 are available in Github, see the Command Line Source Code Snippets paragraph.
Important: How to avoid extension auto-updates during unattended operation.
Related: How to run UI.Vision RPA with the Windows Task Scheduler
TopRunning Concurrent Instances
You can easily run concurrent instances of UI.Vision RPA with Chrome and Firefox via the command line. To do so, you need to start each browser instance with its own profile. For Chrome the command line switch is -profile-directory="Profile 2" and for Firefox it is -p PROFILE_NAME.
Embed and run UI.Vision RPA macros in websites
You can embed macros directly into a website! This is a good option if you need to distribute your macros to a larger numbers of users. Since UI.Vision RPA macros are in standard JSON format, it is very easy to create them dynamically e. g. from info inside a database.
DEMO: This web page contains some embedded macros.
In order to run macros that are embedded in a website you have to first allow it . You do this by checking the "Run embedded macros from public websites" box. This is step 1 in the screenshot below. The default setting is OFF (do not run embedded macros). Once you allow such macros in general, you will see a dialog box asking for permission to run such macros. If you want to avoid this warning dialog for certain websites (for example your own internal website), then you can add this website to the website whitelist (step 2 in the screenshot below):
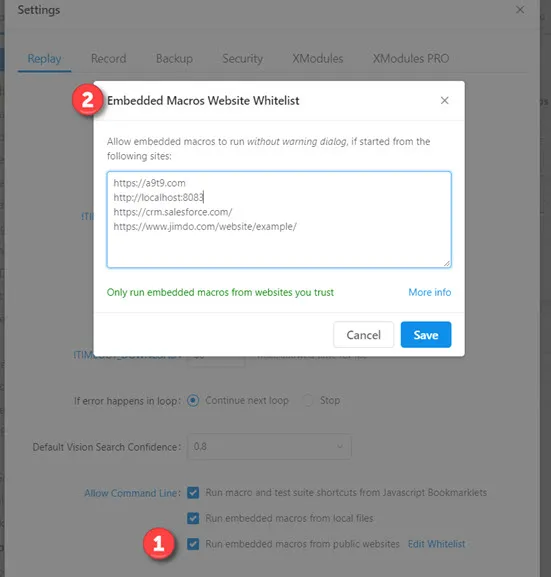
The URLs in the white list are the websites that can contain embedded macros, and that you want to run without warning dialog.
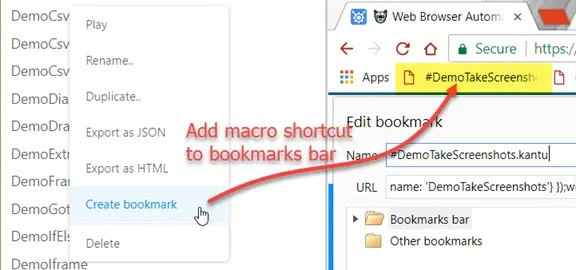
TopRun from bookmarks
In the macro context menu (right-click menu) select "Create bookmark". This adds a shortcut to the macro
to your bookmarks. From now on you can just select the bookmark to run the macro. UI.Vision RPA will open to
run the macro and then close again. But if the macro encounters an error, UI.Vision RPA stays open so you can see what went wrong.
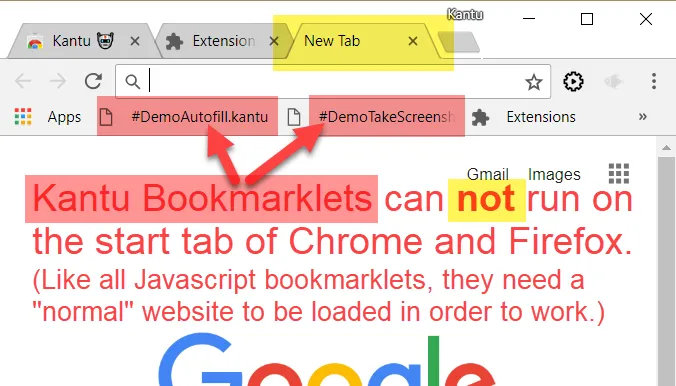
Technically UI.Vision RPA bookmarks are little Javascript snippets (bookmarklets) that start the UI.Vision RPA engine. And thus, like with all
bookmarklets, they do not work on the Google Chrome and Firefox "New Tab" start page. For security reasons, the browser do not run any Javascript on this page. But whenever a "normal" web page is loaded,
the kantu web imacro bookmarks work great.
If you want to make sure Chrome and Firefox are in the foreground while the bookmark macro runs, add the BringBrowsertoForeground command to your macro.
If you want to trigger your macros with keyboard shortcuts you can combine UI.Vision RPA's bookmarklets with the ShortKeys extensions .
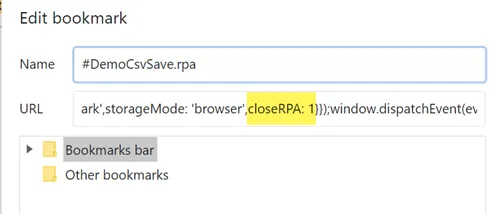 You can change the "close UI.Vision RPA when macro is done" behavior to "keep UI.Vision RPA open when macro is done". To do so, edit the bookmark
and change the flag closeRPA: 1 to closeRPA: 0
in the bookmarklet's Javascript code. Regardless of this flag, the UI.Vision RPA window stays open
if you manually press STOP during the macro run or if the macro stops with an error.
You can change the "close UI.Vision RPA when macro is done" behavior to "keep UI.Vision RPA open when macro is done". To do so, edit the bookmark
and change the flag closeRPA: 1 to closeRPA: 0
in the bookmarklet's Javascript code. Regardless of this flag, the UI.Vision RPA window stays open
if you manually press STOP during the macro run or if the macro stops with an error.
Password Encryption
UI.Vision RPA can store passwords encrypted. You can enable this feature and set a master password in the settings.
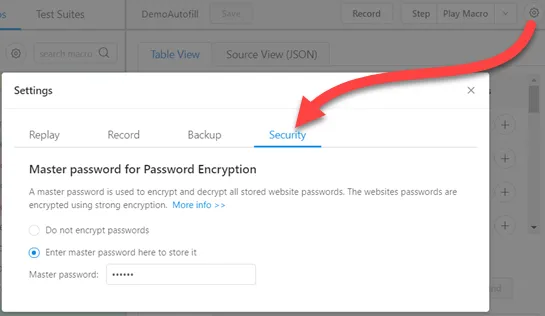
With the master password enabled, every website password that you enter during macro recording is not stored in plain text, but instead as an encrypted string. So instead of having a command like "TYPE | id=password | your-password-here" the recorded command is "TYPE | id=password | __KANTU_ENCRYPTED__f8b53105ebb186d...".
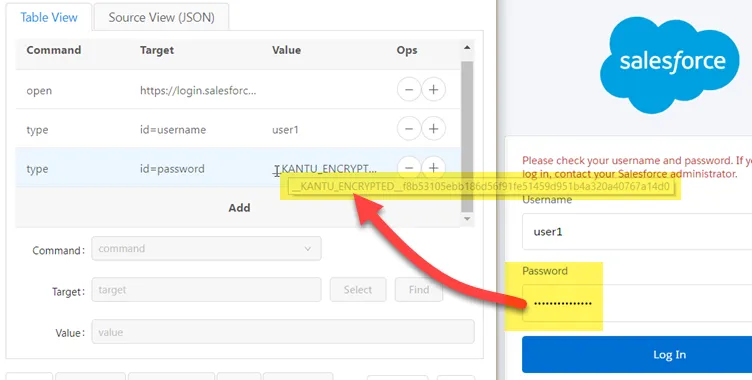
UI.Vision RPA uses 256-bit AES encryption which is considered unbreakable by security experts. Note that if you change the master password later, you need to re-record the password field, so that a new "__KANTU_ENCRYPTED__..." string is created.
TopTest Suites V2.0 (Folders as Testsuites)
Since UI.Vision RPA V5.0 test suites are created on the macros tab, and not the test suites tab. The new concept is straightforward: Every folder is a test suite. To play a test suite, right-click on a folder and select "Test suite: Play all macros in folder". To start the replay at a certain macro, right-click on the macro and select "Replay from here".
You can add or remove macros from a testsuite simply by adding or removing it from a folder. Macros in subfolders are ignored. The replay order is alphabetical, just like the display order.
To start a testsuite from the command line use the folder switch. This runs all macros in the folder.
You can use !GLOBAL_TESTSUITE_STOP_ON_ERROR to tell UI Vision to stop the test suite execution after an error. The default settings is "false", so by default the RPA software continues to run all macros inside a test suite. After a test suite is done, a test report is displayed. It shows the pass/no pass status of each test (macro) and the detailed error messages.
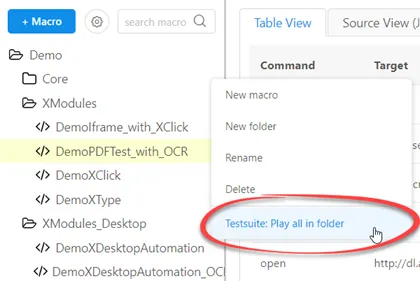 Every folder is now also a test suite. Just drag and drop macros in a folder to build a test suite.
Every folder is now also a test suite. Just drag and drop macros in a folder to build a test suite.
Tip: Another way to combine several macro (tests) into one is the RUN command.
Test Suites (Old-Style, Deprecated)
The old-style Test suites are created on the test suites tab (deprecated) by selecting the test cases (macros) from the drop-down. Click the "+Macro" button to add a new macro to the list. You can also specify how often each macro runs (loops). Test suites itself do not contain macro code, they contain the names of existing macros.
Starting with UI.Vision RPA Version 5.3.x, the old style test suites tab will be hidden by default, when UI.Vision is fresh installed. But the test suites are not lost, just the tab is not displayed by default. You can turn on the old-style test suites tab in the Settings > Selenium > Checkbox (at the bottom).
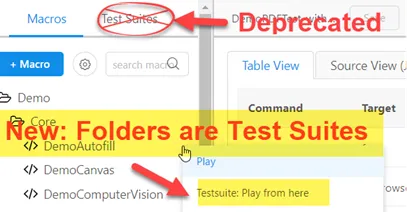 Old-style testsuites are still available for backward compatibility.
Old-style testsuites are still available for backward compatibility.
Once the test suite is completed, a test report summary is written to the log area. The success of each test case is also indicated visually.
To rearrange the order of the macros in the test suite and for other larger changes,
we recommend to edit the JSON source directly. To edit it, either click the "hamburger icon" ☰ displayed to the right of the test suite name,
or right-click the test suite name and then select "Edit source".
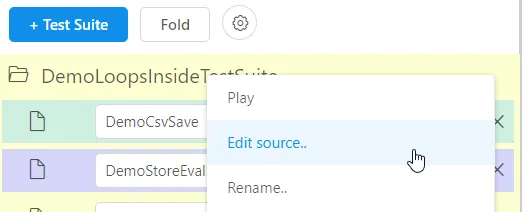
(DEPRECATED OLD-STYLE TESTSUITE) Once you save the edited source code, UI.Vision RPA runs a checks against all available macros to make sure there
are no missing macros or typos.
Global Variables
Global variables: By default, each macro runs independent, no variables are shared. But you can create global variables that are available to every macro and test suite simply by prefixing them with "Global..." (e. g. "globalMyCounter" or "GLOBAL_username"). In other words, variables whose name starts with "Global..." are shared . Global variables keep their value even after the macro has been stopped. Their content is only lost once UI.Vision RPA is closed.
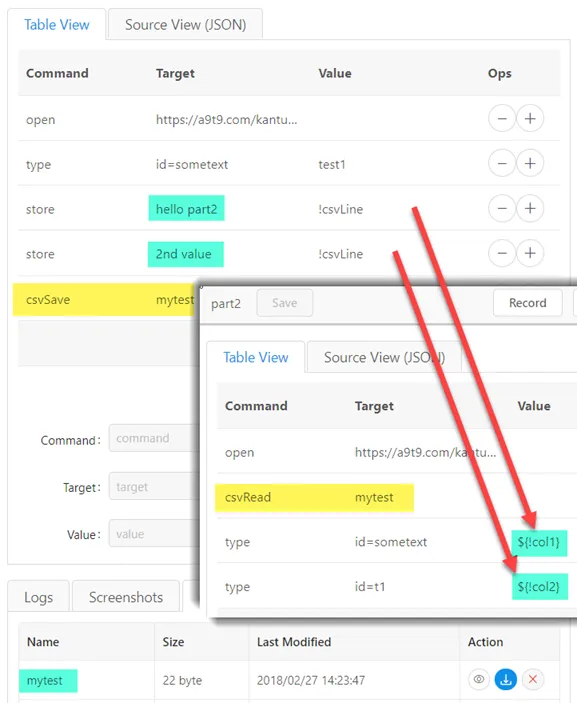
If you want your data to survive a closing of Kantu, then store ("persist") it in a CSV file with
csvSave and
csvRead:
Security and Privacy
The UI Vision RPA core is open-source and guarantees Enterprise-Grade Security. Your data never leaves your machine.
For developers
The UI.Vision RPA core source code is available on GitHub Open-Source RPA (License: GNU).
Migrating to UIV from Selenium IDE or iMacros
UI.Vision RPA is a open-source alternative to iMacros and Selenium IDE, and supports all important Selenium IDE commands. When you invest the time to learn UI.Vision RPA, you learn Selenium IDE at the same time. You can even import Selenium IDE test cases.
Top